Words are not fixed objects
When people first learn about embeddings, the idea sounds simple: take a word and convert it into a list of numbers so a model can work with it.
That is true, but it is only the beginning.
The word "bank" in "I deposited money in the bank" does not mean the same thing as "bank" in "We sat on the bank of the river." If a model gives both uses of bank the exact same vector, it is already starting with the wrong assumption.
That is the core reason contextual embeddings matter. They let a model represent a word based on the words around it, not as a fixed dictionary entry.
In this post, we will cover:
- What a general or static embedding is
- What a contextual embedding is
- Why transformers depend on contextual embeddings
- How contextual embeddings are calculated using self-attention
- A simple worked example with real intuition
One note on terminology: people sometimes say general embedding for the older style of embedding, but the more common technical term is static embedding. I will use both ideas together here.
What is an embedding?
An embedding is a dense numeric representation of a token, word, sentence, image, or another piece of data.
Instead of representing a word as a giant one-hot vector like:
dog = [0, 0, 0, 1, 0, 0, 0, ...]we represent it as a compact learned vector like:
dog = [0.18, -0.42, 0.77, 0.05, ...]The magic is that similar concepts often end up near each other in vector space. For example, dog, puppy, and pet may be closer to one another than dog and airplane.
This gives neural networks a much richer starting point than raw IDs.
Static embeddings: one word, one vector
Older NLP models such as Word2Vec, GloVe, and in many cases fastText learn a fixed embedding table.
That means:
- every time the token bank appears, it starts with the same vector
- every time the token apple appears, it starts with the same vector
- the embedding does not change based on the sentence
So a static embedding table might look conceptually like this:
| Word | Embedding |
|---|---|
| bank | [0.4, -0.2, 0.9, ...] |
| money | [0.8, 0.1, 0.3, ...] |
| river | [-0.5, 0.7, -0.1, ...] |
This was a huge improvement over one-hot encoding because it captured useful semantic structure. Word analogies such as:
king - man + woman ≈ queenbecame possible.
But static embeddings have a major weakness: one token gets one meaning.
Why static embeddings are not enough
Language is full of ambiguity.
- bank can mean a financial institution or the side of a river
- bat can mean an animal or a piece of sports equipment
- light can mean illumination or something not heavy
Static embeddings struggle because they collapse all senses into one fixed vector.
They also miss other kinds of context:
- sentiment: "This movie is sick" can be praise or criticism depending on usage
- syntax: the role of a word changes depending on sentence structure
- long-range dependency: a word may depend on another word far away in the sentence
- task nuance: the meaning needed for translation, summarization, and question answering is not always the same
In short, static embeddings know something about language, but not enough about the current sentence.
Contextual embeddings: one token, many possible vectors
A contextual embedding is a representation of a token after the model has looked at its surrounding context.
That means the token bank can become one vector in:
I deposited money in the bank.and a different vector in:
We sat on the bank of the river.This is the key difference:
| Property | Static embedding | Contextual embedding |
|---|---|---|
| Vector for a word | Fixed | Changes with context |
| Handles ambiguity well | No | Yes |
| Captures sentence meaning | Weakly | Strongly |
| Used in classic NLP pipelines | Often | Less often |
| Used in transformers | Only as the starting lookup | Yes, throughout the model |
A very important detail: in transformers, we still begin with a token embedding lookup table. But that lookup is only the starting point. After self-attention layers mix information across tokens, the hidden state for each token becomes contextual.
That hidden state is what people usually mean by a contextual embedding.
Why transformers use contextual embeddings
Transformers were designed to let each token look at other relevant tokens in the sequence. This solves a deep problem in language: words do not carry full meaning by themselves.
Consider these sentences:
- "The bank approved the loan."
- "The fisherman rested on the bank."
If the model used only a static vector for bank, it would blur these two meanings together. But a transformer can make bank attend to words like approved and loan in the first sentence, and to fisherman in the second.
That is why contextual embeddings are so useful in transformers:
- they resolve ambiguity
- they capture relationships between words
- they allow the same token to mean different things in different places
- they improve downstream tasks like translation, search, QA, summarization, and generation
Without contextual embeddings, a transformer would lose one of its biggest strengths.
The big picture: where contextual embeddings come from
The heart of the transformer is self-attention.
The core equation is:
Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k)) VIf that looks intimidating, do not worry. The idea is simpler than the notation.
- Q means Query: what this token is looking for
- K means Key: what each token offers
- V means Value: the information each token can pass along
A contextual embedding is produced when a token gathers weighted information from other tokens through that attention process.
Step by step: how contextual embedding is calculated
Let us walk through a sentence:
I deposited money in the bank1. Tokenize the input
The sentence is split into tokens:
[I, deposited, money, in, the, bank]Each token gets an ID.
2. Look up the initial token embeddings
Each token ID is mapped to a learned embedding vector from an embedding matrix.
e_I, e_deposited, e_money, e_in, e_the, e_bankAt this point, bank is still just its basic lookup vector. It is not contextual yet.
3. Add positional information
Transformers need to know order, so we add positional embeddings or positional encodings:
h_i^0 = e_i + p_iNow each token has both content information and position information.
4. Create Query, Key, and Value vectors
For each token representation h_i, the model applies learned linear projections:
q_i = h_i W_Q
k_i = h_i W_K
v_i = h_i W_VFor the whole sentence, this becomes three matrices:
Q = H W_Q
K = H W_K
V = H W_VThis is the stage often shown in attention diagrams: every token gets its own query, key, and value vector.
Here is the same flow in a more visual form:
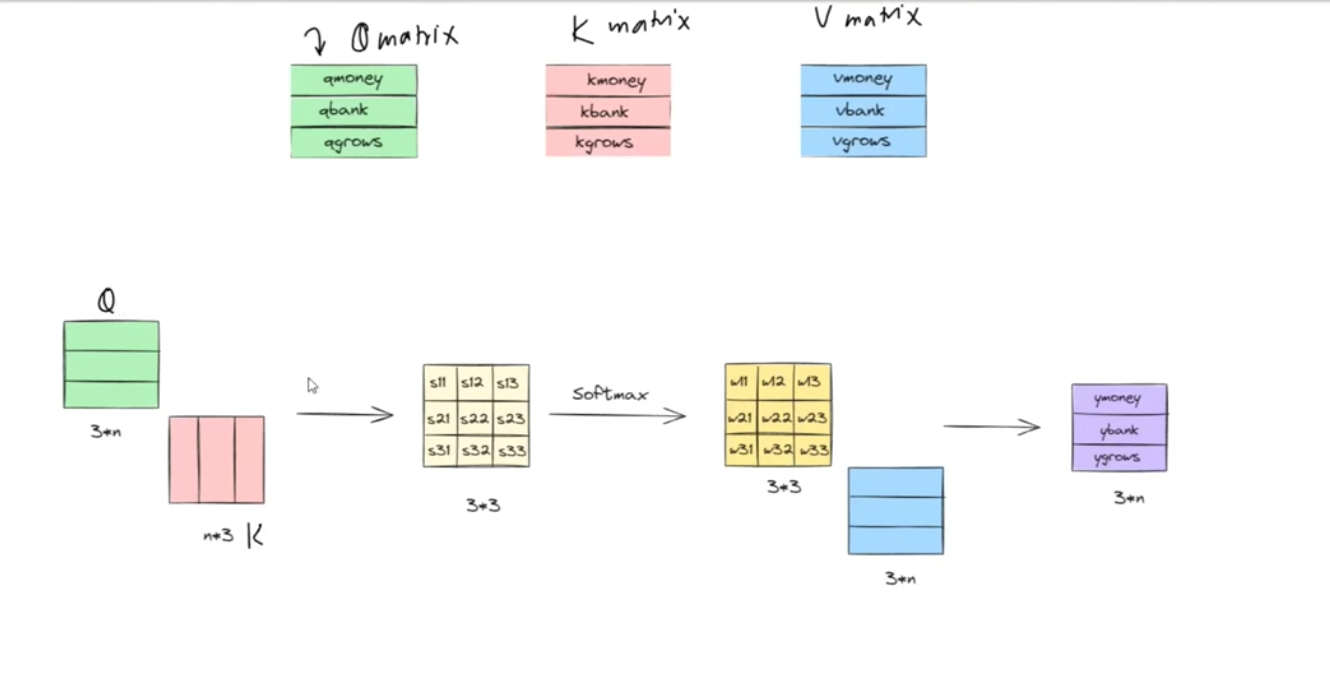
The sketch shows the Q, K, and V projections, the score matrix from QK^T, the softmax weighting step, and the final weighted combination of the value vectors.
5. Compute attention scores
For each token, we compare its query with every key using a dot product.
For token i attending to token j:
score(i, j) = (q_i · k_j) / sqrt(d_k)This tells us how relevant token j is when token i builds its updated representation.
If we stack all pairwise scores together, we get a score matrix:
S = (QK^T) / sqrt(d_k)6. Apply softmax
The raw scores are turned into probabilities:
A = softmax(S)Each row of A sums to 1. A row tells us how much attention one token pays to all tokens in the sequence.
7. Mix the Value vectors
Now we take a weighted sum of the value vectors:
Z = A VThis is the crucial step.
The updated representation for token i is the weighted combination of the value vectors from all tokens. So if bank strongly attends to money and deposited, its new vector will move toward a financial meaning.
That weighted sum is the beginning of the token's contextual embedding.
8. Use multiple heads
Transformers do not do this just once. They use multi-head attention.
That means several separate sets of W_Q, W_K, and W_V learn different relationships in parallel:
- one head may focus on syntax
- one may track coreference
- one may focus on nearby words
- one may capture long-range semantic links
The outputs of all heads are concatenated and projected again.
9. Pass through feed-forward layers and repeat
After attention, the model applies:
- residual connections
- layer normalization
- a position-wise feed-forward network
Then the process repeats across many layers.
By the final layers, each token representation contains rich information from the rest of the sentence. That final hidden state is usually what we call the contextual embedding.
A simple intuition for the attention diagram
If you think about a standard attention diagram with Q, K, and V blocks:
QK^Ttells you how strongly each token relates to every other tokensoftmaxturns those relationships into weights- multiplying by
Vmixes information from all tokens - the output is the new context-aware representation
So the contextual embedding is not stored in a static dictionary. It is computed on the fly from the current sequence.
Worked example: how "bank" changes with context
Let us compare two contexts for the token bank.
Sentence A
money bank loanImagine the attention weights for the token bank become:
[0.51, 0.19, 0.30]meaning:
- 51% attention to money
- 19% to bank itself
- 30% to loan
Now suppose the value vectors are:
money = [1.0, 0.0]
bank = [0.5, 0.5]
loan = [0.8, 0.2]The contextual embedding for bank becomes the weighted sum:
0.51 * [1.0, 0.0]
+ 0.19 * [0.5, 0.5]
+ 0.30 * [0.8, 0.2]
= [0.845, 0.155]That output leans strongly toward the first dimension, which we can imagine as the "financial" direction.
Sentence B
river bank waterNow imagine the attention weights for bank are:
[0.35, 0.15, 0.50]and the value vectors are:
river = [0.0, 1.0]
bank = [0.5, 0.5]
water = [0.1, 0.9]Then the new contextual embedding becomes:
0.35 * [0.0, 1.0]
+ 0.15 * [0.5, 0.5]
+ 0.50 * [0.1, 0.9]
= [0.125, 0.875]Now the vector leans strongly toward the second dimension, which we can imagine as the "river-side" direction.
The exact numbers in real transformers are much larger and learned automatically, but the logic is the same: same token, different context, different embedding.
An important subtlety
Contextual embeddings are not usually created in a single dramatic step. They become richer layer by layer.
- early layers often capture local and syntactic information
- middle layers often capture phrase-level meaning
- deeper layers often capture higher-level semantics and task-relevant structure
So if someone asks, "What is the contextual embedding of a word in a transformer?" the honest answer is often:
it is the hidden state of that token at a chosen layer, usually a later one or the final layer
Why this matters in practice
Contextual embeddings are one of the main reasons transformer models perform so well.
They help with:
- search and retrieval: queries and documents can be compared in a context-aware way
- translation: the same word can map to different outputs based on sentence meaning
- question answering: the model can locate the relevant part of the passage
- text generation: every next token prediction depends on contextual understanding
- classification: sentiment, intent, and topic all depend on usage, not just raw words
This is also why modern NLP moved so aggressively from static embeddings to transformer-based representations.
Final takeaway
Static embeddings assign one learned vector to each token. They are useful, compact, and historically important, but they treat meaning as fixed.
Contextual embeddings do something much closer to how language actually works. A token begins with a base embedding, then the transformer updates it by looking at other tokens through self-attention:
contextual embedding = softmax((QK^T) / sqrt(d_k)) Vplus multi-head attention, feed-forward layers, residual connections, and repeated stacking across layers.
That is why transformers use contextual embeddings: meaning is not stored in isolated words. Meaning emerges from relationships.