The tiny term everybody memorizes
If you have seen the transformer attention formula before, you have probably seen this line:
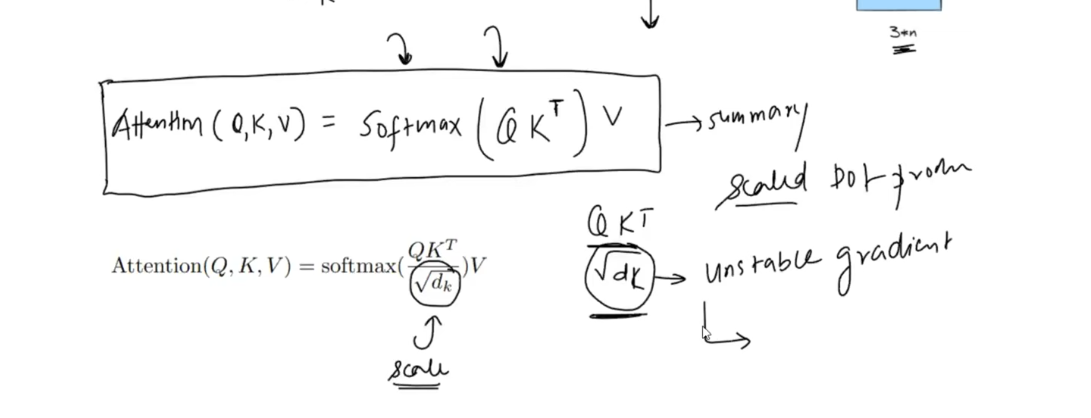
Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k)) VMost people remember the formula. Fewer remember why that sqrt(d_k) is there.
At first glance, it looks like a small technical detail. In practice, it is one of the reasons attention remains trainable when vector dimensions get large.
This post explains the idea in plain English:
- what goes wrong if we use
QK^Tdirectly - why higher dimensions make the problem worse
- how softmax turns that into unstable learning
- why dividing by
sqrt(d_k)is the right fix
First, what attention is trying to do
In self-attention, every token creates three vectors:
- a query: what am I looking for?
- a key: what kind of information do I contain?
- a value: what information should I pass forward?
The attention score between two tokens is based on a dot product:
score(i, j) = q_i . k_jIf the dot product is high, token i pays more attention to token j. If it is low, token j matters less for that update.
That basic idea is elegant. The trouble starts when the vectors get wider.
Where the problem comes from
A dot product is a sum across dimensions:
q . k = q_1 k_1 + q_2 k_2 + ... + q_dk k_dkEvery extra dimension adds another term.
If the query and key components are roughly centered around zero with unit variance, then each product q_m k_m also has mean near zero and variance near one. When we add d_k such terms together, the variance of the whole dot product grows linearly:
Var(q . k) = d_kThat means the standard deviation grows like:
Std(q . k) = sqrt(d_k)So as d_k gets larger, the raw attention scores naturally spread out more.
This is the core issue.
Why large variance becomes a training problem
Attention does not stop at the dot product. We pass the scores through softmax:
softmax(scores)Softmax is very sensitive to score magnitude.
If the values are moderate, softmax produces a useful distribution where multiple tokens can still contribute. But when one score becomes much larger than the others, softmax becomes extremely sharp and collapses toward a one-hot distribution.
Here is a simple example.
Suppose a token is comparing three candidates and produces these raw scores:
[3, 1, 0]The softmax is approximately:
| Scores | Softmax output |
|---|---|
[3, 1, 0] | [0.844, 0.114, 0.042] |
That is a strong preference, but the model still gives some probability mass to the other tokens.
Now imagine the same relative pattern after the dot product grows larger in a higher-dimensional space:
[12, 4, 0]The softmax becomes:
| Scores | Softmax output |
|---|---|
[12, 4, 0] | [0.9997, 0.0003, 0.000006] |
Now attention is almost entirely locked onto one token.
That is not just "confident." It is too sharp.
A language example
Take the sentence:
The bank approved the loan yesterday.When the model updates the token bank, it might compare that token against nearby words like approved, loan, and yesterday.
An attention distribution like this is reasonable:
[approved: 0.62, loan: 0.28, yesterday: 0.10]That says: "approved matters most, loan also matters, and yesterday matters a bit."
But if raw dot products explode and softmax saturates, the distribution can become something closer to:
[approved: 0.999, loan: 0.001, yesterday: 0.000]Now the model is effectively ignoring information that may still be useful.
During training, that is dangerous because the model stops learning nuanced relationships and starts behaving like a brittle winner-take-all lookup.
Why this hurts gradients
The softmax problem is not only about bad probabilities. It is also about bad gradients.
When a softmax output is near 0 or 1, its derivative becomes very small. A handy way to remember this is:
for a probability p, the local sensitivity scales like p(1 - p)So:
| Probability | p(1 - p) |
|---|---|
0.50 | 0.25 |
0.90 | 0.09 |
0.99 | 0.0099 |
0.999 | 0.000999 |
As attention probabilities become extreme, the gradients shrink fast.
That means the model has a harder time adjusting the less dominant scores. The biggest score keeps winning, and the smaller ones barely get a chance to learn.
This is why people often say unscaled dot-product attention can lead to unstable or inefficient training in high dimensions.
Why dividing by sqrt(d_k) fixes it
We already saw that the raw dot product tends to have:
Var(q . k) = d_kSo its spread grows with the dimension.
If we divide by sqrt(d_k), the variance becomes:
Var((q . k) / sqrt(d_k)) = d_k / d_k = 1That is exactly what we want.
Instead of letting the attention scores get wider and wider as the head dimension grows, we keep them on a more stable scale before softmax sees them.
This does not remove differences between tokens. It simply keeps those differences in a range where softmax can still behave sensibly.
The same example after scaling
Let us reuse the earlier scores:
[12, 4, 0]If d_k = 16, then:
sqrt(d_k) = 4After scaling:
[12, 4, 0] / 4 = [3, 1, 0]And the softmax changes from:
[0.9997, 0.0003, 0.000006]to:
[0.844, 0.114, 0.042]That second distribution is still decisive. It still prefers the strongest match. But it is no longer so extreme that everything else becomes invisible.
This is the real purpose of the scaling term: keep attention confident without making it numerically overconfident.
Why sqrt(d_k) and not d_k?
This is an important question.
If the variance grows like d_k, then the standard deviation grows like sqrt(d_k). To normalize the spread, we divide by the thing that scales like the spread: sqrt(d_k).
If we divided by d_k instead, we would usually overcorrect.
Using the same example:
[12, 4, 0] / 16 = [0.75, 0.25, 0]The softmax becomes approximately:
[0.481, 0.292, 0.227]Now the distribution is arguably too flat. The model loses useful contrast between the best match and the weaker matches.
So:
- no scaling: softmax gets too sharp
- divide by
d_k: softmax gets too flat - divide by
sqrt(d_k): softmax keeps a healthy temperature
That middle path is the reason the original transformer paper chose this term.
A compact intuition
Here is the simplest mental model I know:
Every extra dimension is another vote in the dot product.
As you add more dimensions, the total score naturally gets louder, even if the underlying relationship between tokens has not changed. Dividing by sqrt(d_k) works like a volume control. It makes attention scores comparable across different vector sizes before softmax turns them into probabilities.
So the scaling term is not a random trick. It is a calibration step.
The final formula
This is the full scaled dot-product attention equation used in transformers:
Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k)) VRead it like this:
- compare queries and keys with a dot product
- scale the scores so their variance stays under control
- turn those scores into attention weights with softmax
- use those weights to mix the value vectors
That tiny sqrt(d_k) term is what keeps the whole mechanism well-behaved as dimensions increase.
If you remember one thing
The reason we divide by sqrt(d_k) is simple:
without scaling, dot-product variance grows with dimension, softmax becomes too peaky, gradients get tiny, and training becomes harder.
Scaling by 1 / sqrt(d_k) keeps the score distribution stable, which helps attention stay expressive, trainable, and numerically sane.