The simple problem positional encoding solves
Self-attention is one of the smartest ideas in deep learning. It lets each token look at the other tokens in a sentence and decide which ones matter most.
That is why transformers can build rich contextual representations. The word bank can attend to river or money and take on the right meaning.
But self-attention has a blind spot.
By itself, it does not know where a token sits in the sequence.
Consider these two sentences:
The dog chased the cat.
The cat chased the dog.The words are almost the same. Only the order changes. But the meaning changes completely.
Without extra positional information, self-attention sees the same set of token identities interacting with one another. It can learn relationships between words, but it does not get a built-in sense of "first", "second", or "third".
That is why transformers need positional encoding: it injects order into an architecture that otherwise treats the input like a set rather than an ordered sentence.
Why self-attention alone cannot tell who did what
Self-attention builds queries, keys, and values from the input tokens and then compares them.
The core equation is:
Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k)) VThis is powerful because every token can directly interact with every other token, and it can do that in parallel.
But notice what is missing from that formula: there is nothing inside it that says token 0 came before token 1, or token 4 came after token 2. If we do not inject positional information somewhere else, the mechanism has no native concept of sequence order.
People often describe this by saying self-attention is permutation-invariant or order-agnostic. More precisely, without positional information the layer is permutation-equivariant: if you shuffle the tokens, the outputs shuffle with them. Either way, the important result is the same: the model does not automatically know which token came first.
A good mental model is this:
- self-attention is excellent at deciding which words are related
- positional encoding answers where each word is located
We need both.
Here is a classic order-sensitive example:
Nitish killed lion.
Lion killed Nitish.Or, in a less dramatic version:
The teacher praised the student.
The student praised the teacher.The same words appear, but the roles flip because the order flips.
If a model only knows the word identities and not their positions, it cannot reliably tell subject from object just from the sequence layout. That is the core limitation positional encoding fixes.
Why a simple counting scheme is not enough
The most obvious idea is to number the positions:
word 1 -> position 1
word 2 -> position 2
word 3 -> position 3
...That sounds reasonable, but raw counting is a weak solution if you feed it directly into the model.
1. The values grow without bound
Position 5 and position 5000 are on completely different numeric scales. Neural networks usually behave better when inputs stay in controlled ranges.
2. A single integer is too crude
A raw scalar like 17 does not give the model a rich, high-dimensional description of position. It only says "this token is at slot 17" and nothing more.
3. Simple integers do not naturally express repeating structure
Language often depends on both local order and long-range distance. A single growing number does not give the model a clean multi-scale pattern to work with.
4. Raw integers do not make relative shifts easy to learn
The model does not just need absolute positions. It also needs patterns like:
- one word is 1 step away
- another is 3 steps away
- a dependency spans 10 tokens
- two phrases are far apart but still connected
A better positional signal should help with both absolute order and relative distance.
To be precise, positions can also be learned. Many modern models do exactly that. The real problem is not counting itself. The problem is assuming a single raw integer is rich enough to represent everything the model needs to know about position.
| Approach | Good at | Main weakness |
|---|---|---|
| Raw position numbers | Telling you the slot index | Unbounded, one-dimensional, weak for relative structure |
| Sinusoidal position vectors | Smooth, bounded, multi-scale patterns | Less intuitive at first glance |
This is where the original transformer paper made a beautiful choice: sinusoidal positional encoding.
The key idea: represent position as a vector of waves
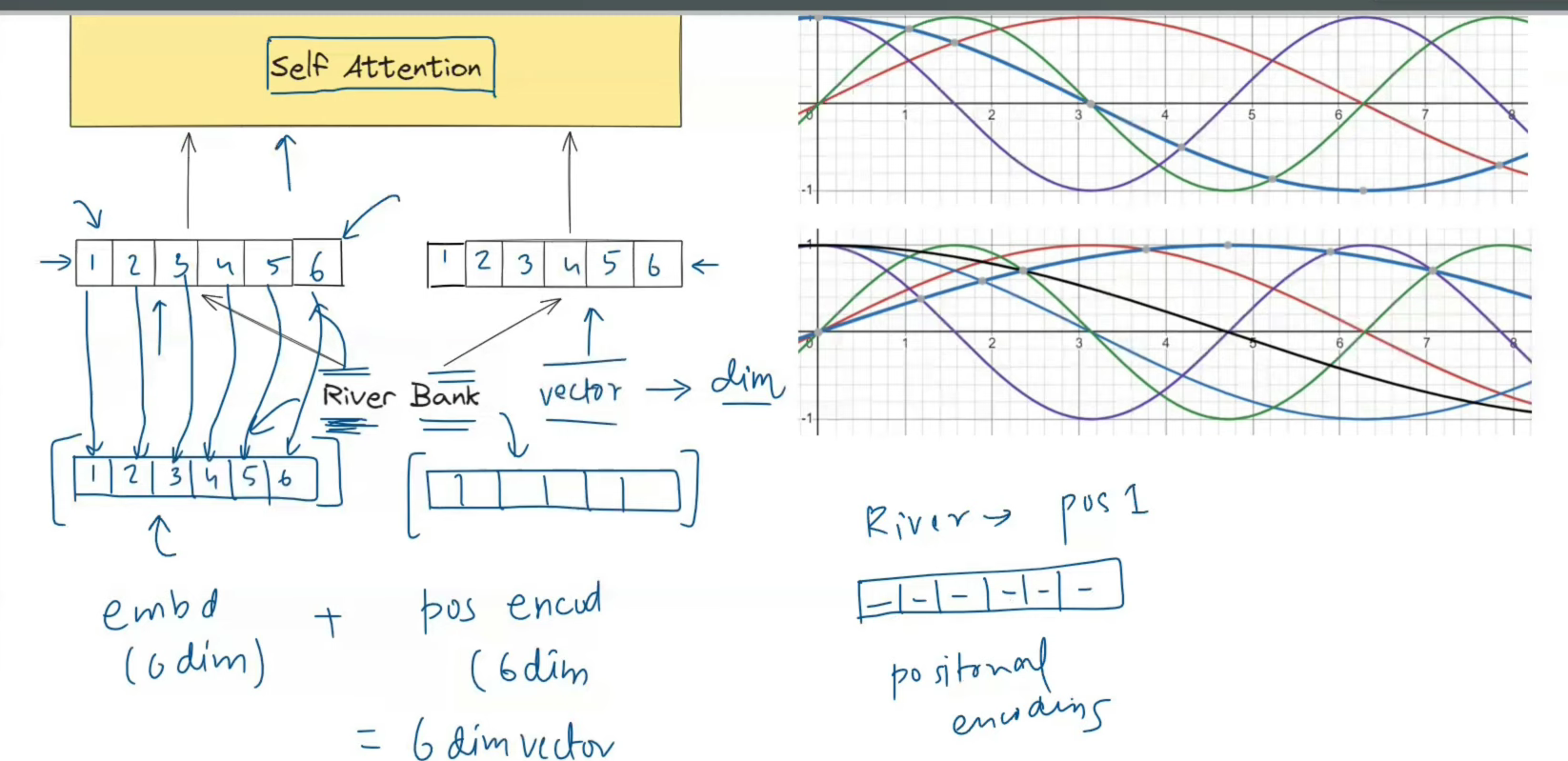
Instead of giving each position one number, the transformer gives each position a full vector.
If the model dimension is d_model = 6, then position 3 gets a 6-dimensional positional vector. If d_model = 512, then position 3 gets a 512-dimensional positional vector.
Why a vector?
Because one number is too weak, but many coordinated numbers can create a unique signature for each location in the sequence.
The clever part is that each dimension uses a wave:
- some dimensions change quickly from one token to the next
- some change slowly over long spans
- even dimensions use sine
- odd dimensions use cosine
You can imagine each pair of dimensions as a tiny clock:
- fast clocks move a lot every step
- slow clocks barely move
- together, all the clocks give each position its own timestamp
That is why positional encoding plots look like layered waves.
Why sine and cosine work so well
Sine and cosine solve several problems at once.
They are bounded
Their values always stay between -1 and 1.
That means the model does not see position numbers exploding as the sequence gets longer.
They are continuous
Moving from position 10 to position 11 creates a smooth change in the encoding instead of a harsh jump in scale.
That smoothness is much friendlier for learning.
They are periodic
A wave repeats, which means position is not encoded as a rigid staircase. The model gets patterns and rhythms, not just raw counts.
Sine alone would repeat too much, so we use many frequencies
If you used only one sine curve, different positions would eventually land on the same value again. That would create collisions.
The fix is to use many sine and cosine curves at different frequencies. Then each position is described by a combination of fast and slow waves, which makes the overall vector highly distinctive.
A nice intuition is:
- one wave is a weak fingerprint
- many waves together become a strong fingerprint
The original formula from Attention Is All You Need
The paper defines sinusoidal positional encoding like this:
PE(pos, 2i) = sin(pos / 10000^(2i / d_model))
PE(pos, 2i + 1) = cos(pos / 10000^(2i / d_model))Let us decode that slowly.
posis the token position in the sequenced_modelis the embedding sizeipicks which sine-cosine pair we are computing2imeans even dimensions use sine2i + 1means odd dimensions use cosine
The denominator controls the frequency.
For small dimensions, the frequency is high, so the values change quickly from one position to the next.
For large dimensions, the frequency is low, so the values change slowly across the sentence.
That creates a layered representation of position across the embedding space.
A tiny intuition for d_model = 6
Suppose we have six positional dimensions.
- dimensions 0 and 1 might change quickly
- dimensions 2 and 3 might change more slowly
- dimensions 4 and 5 might change very slowly
So position 1 and position 2 look similar but not identical. Position 1 and position 100 look very different across the full vector. And nearby positions preserve a smooth relationship instead of jumping randomly.
That is exactly what we want.
Why transformers add the position vector instead of concatenating it
Once we have a word embedding and a positional encoding, we need to combine them.
The original transformer does this:
input_to_transformer = token_embedding + positional_encodingnot this:
input_to_transformer = concat(token_embedding, positional_encoding)This design choice is simple but important.
Addition keeps the dimensionality fixed
If the token embedding is 512-dimensional and the positional encoding is also 512-dimensional, adding them still gives a 512-dimensional vector.
Concatenation would turn that into 1024 dimensions, which means more parameters, more compute, and slower training.
Addition is enough for the model to recover both signals
Because the embedding and the positional vector share the same space, later layers can learn to use the parts that matter.
The model can read semantic content from the token embedding and order information from the positional pattern without paying the cost of a larger representation.
Addition keeps every layer aligned
Each token enters the transformer with the same shape the rest of the network expects. That keeps the architecture clean.
A simple example:
- the word embedding for
rivertells the model what the token means - the positional encoding for position 1 tells the model where it appears
- adding them gives a single vector that says both what and where
A worked example with sentence order
Take these two sentences:
The dog chased the cat.
The cat chased the dog.Without positional encoding, the model can identify the tokens dog, cat, and chased, but it has no built-in signal telling it which noun came first and which came later.
With positional encoding, the representations are different right from the input:
- in sentence 1,
dogis mixed with the position-1 vector andcatwith the position-4 vector - in sentence 2,
catis mixed with the position-1 vector anddogwith the position-4 vector
Now the transformer is not only seeing the same words. It is seeing the same words at different places.
That extra information is enough for attention layers to build order-aware meaning.
This is why positional encoding is not a minor detail. It is one of the pieces that makes transformers understand sentences instead of bags of words.
The binary encoding analogy
A surprisingly good intuition is to compare positional encoding to binary numbers.
In binary:
- the rightmost bit changes very quickly
- the next bit changes more slowly
- higher bits change even more slowly
For example:
0 = 0000
1 = 0001
2 = 0010
3 = 0011
4 = 0100Sinusoidal positional encoding behaves like a continuous, smooth version of that idea.
- low dimensions change quickly, like low-order bits
- high dimensions change slowly, like high-order bits
- the full vector acts like a multi-scale address for the token
It is not literally binary, but it helps explain why every dimension changes at a different rate.
Binary gives unique addresses using sharp flips. Positional encoding gives unique addresses using smooth waves.
The deep insight: it also carries relative position information
This is the part many people miss.
Sinusoidal positional encoding does not only label absolute positions like "token 5" or "token 12". It also makes relative shifts easier to express.
For one sine-cosine pair with angular frequency w, we can write:
sin(w(p + k)) = sin(wp)cos(wk) + cos(wp)sin(wk)
cos(w(p + k)) = cos(wp)cos(wk) - sin(wp)sin(wk)That means the encoding at position p + k can be computed from the encoding at position p using a linear transformation that depends only on the offset k.
In plain English:
- moving 1 step to the right changes the wave by a fixed amount
- moving 2 steps changes it by another fixed amount
- the same relative move creates a consistent mathematical shift
A great mental model is a clock.
If each sine-cosine pair is a clock hand, then moving from position p to position p + k is like rotating every clock by a fixed angle. Fast clocks rotate more, slow clocks rotate less, but the shift is structured and predictable.
That is why the model can more easily learn ideas like:
- the next word
- three tokens earlier
- far away but still connected
So positional encoding helps with both:
- absolute position: where am I?
- relative position: how far away is that other token?
Why this matters so much inside a transformer
A transformer needs two kinds of information at the same time:
- content information: what the tokens mean
- order information: where the tokens appear
Self-attention is amazing at content interaction. Positional encoding supplies the missing order signal.
Together they let the model answer questions like:
- Which noun is the subject?
- Which adjective modifies which noun?
- Which verb belongs to which entity?
- Which earlier word does this pronoun refer to?
- How far apart are two related words?
Without positional encoding, self-attention would still compare tokens, but it would have a much weaker understanding of sentence structure.
A quick note on modern variants
The original transformer paper used fixed sinusoidal positional encoding, and it is still the cleanest way to understand the core idea.
Modern architectures sometimes use other approaches, such as:
- learned positional embeddings
- relative position bias
- rotary positional embeddings (RoPE)
These methods change how position is injected, but they all exist for the same reason:
the model must know order.
So even when the implementation changes, the need does not.
Final takeaway
Self-attention gives transformers context, but not order.
Positional encoding is the mechanism that tells the model where each token lives in the sequence. The original sine-cosine design is elegant because it keeps values bounded, makes nearby positions change smoothly, creates unique multi-frequency signatures, and even helps the model reason about relative distance.
If you want one sentence to remember, use this one:
Word embeddings tell a transformer what a token is. Positional encoding tells it where that token is. Only together can the model read a sentence in the correct order.